V mojí knížce Analýza klíčových slov: Návod krok za krokem popisuji, jak se má dataset klíčových slov pročistit pomocí nástroje OpenRefine (str. 80).
Tento článek jsem se rozhodl napsat jako doplnění, nebo rozšíření stávajícího obsahu. V knížce popisuji manuální postup očištění datasetu, který nemusí vadit při menších klíčovkách, ale při větší analýza čítající tisíce frází je tento krok zdlouhavý a dá se nahradit automatizovaným procesem pomocí skriptu, který si krok za krokem popíšeme níže.
Rád bych tu poděkoval Martinovi Žatkovičovi z Taste, od kterého jsem tento návod převzal. Kdo chce, může se podívat na jeho článek Analýza klíčových slov na maximum - automatizace.
Nyní se již do toho můžeme pustit. Na začátku rychle naznačím, proč se metodou automatizace v OpenRefine vydat.

Výhody automatizovaného procesu pomocí skriptu
- Nízká míra chybovosti
- Extrémní rychlost zpracování v porovnání s ručním procházením datasetu
- Součet hledanosti všech klastrovaných dat přiřazená k výslednému klíčovému slovu, kterou jinak při manuálním výběru neděláme
Nevýhody
- Skript vybere nejhledanější klíčové slovo z daného setu slov stejného významu a ne vždy se jedná o gramaticky správnou variantu s interpunkcí
Postup aplikace skriptu, který automaticky vybere nejhledanější klíčová slova v OpenRefine
Nyní se již nacházíme ve fázi, kdy máme pohromadě všechna klíčová slova bez duplicit a máme u nich zjištěnou hledanost.
1. Příprava dat v excelu
Již v excelu si můžeme data malinko předchystat, o to rychleji nám to následně půjde v OpenRefine.
Dataset bude mít 3 sloupce - Keyword, Keyword-bu, Search. Keyword-bu představuje sloupec s budoucími klíčovými slovy, se kterými budeme pracovat, Search je hledanost jednotlivých frází. Pojmenování musíte zachovat, jak je uvedené, jinak vám skript nebude fungovat správně.
2. Import dat do OpenRefine
Postupujte dle návodu v knížce Analýza klíčových slov: Návod krok za krokem, strana 81. Po importu bude soubor vypadat jak na obrázku níže.
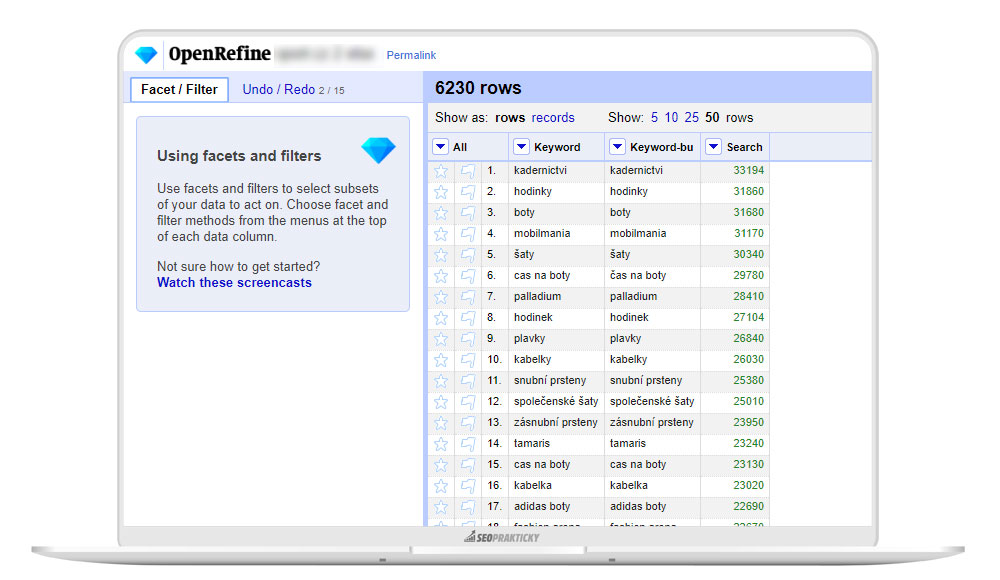
3. Klastrování dat (shlukování / clusterování klíčových dat)
Nyní se již vrhneme na očištění našich dat.
Budeme se chtít zbavit všech klíčových slov s překlepy, jiným pořadím slov a dalšími chybami. Všechny tato slova se budeme snažit shluknout do jediného, správného výrazu. Použijeme k tomu tzv. clustrování dat za pomoci shlukové analýzy, kterou za nás udělá OpenRefine.
Shluková analýza (též clusterová analýza, anglicky cluster analysis) je vícerozměrná statistická metoda, která se používá ke klasifikaci objektů. Slouží k třídění jednotek do skupin (shluků) tak, aby si jednotky náležící do stejné skupiny byly podobnější než objekty z ostatních skupin.
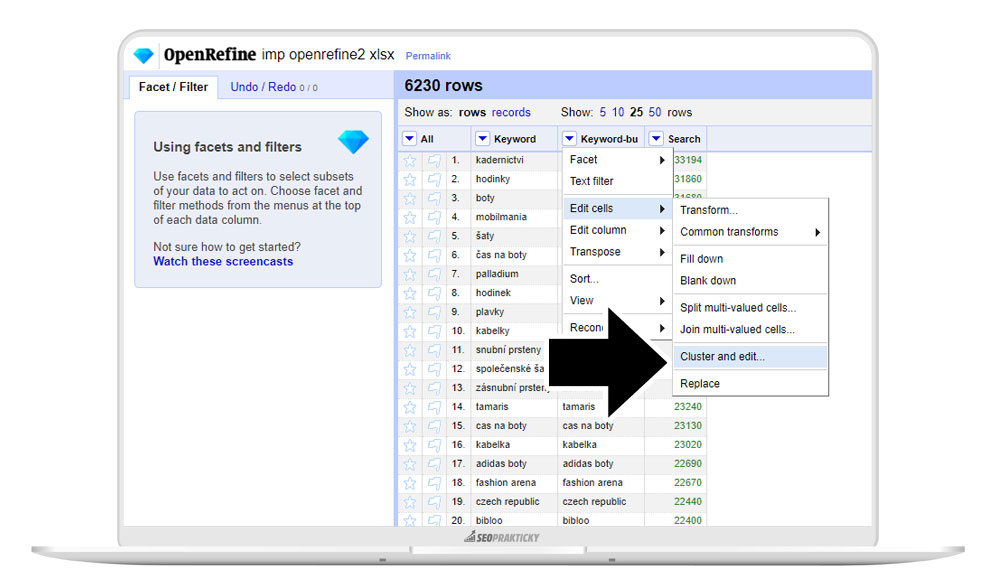
V nabídce u sloupce s Keyword zvolte Edit cells -> Cluster and Edit (Editovat buňky -> Sloučit a editovat).
Na obrázku níže ukazuji klastrování dat na sloupci Keyword-bu, ale dělejte ho na sloupci Keyword. Udělal jsem jenom špatný screenshot a už nebyla vůle to zpětně v grafice měnit :-).
Klikněte na Select All a poté na Merge Selected and Recluster.
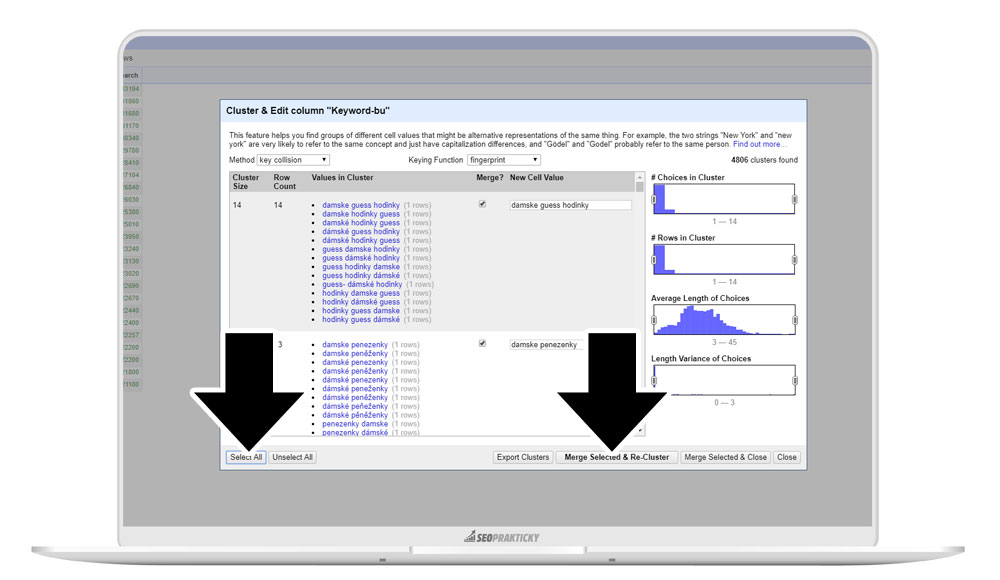
V knize popisuji další možné varianty klastrování. Pakliže k nim nepřistoupíme a vystačíme si s funkcí fingerprint, můžeme kliknout na Close.
4. Vložení skriptu přes funkci Apply
Nyní máme provedenou základní klasterizaci, ale dataset ještě potřebujeme pročistit a k tomu nám poslouží připravený skript. Ten nám vyhledá ty nejhledanější slova.
Nejprve klikněte na položku Undo / Redo v levé horní části obrazovky. Poté se vám zpřístupní funkce Apply, kam nakopírujeme skript.
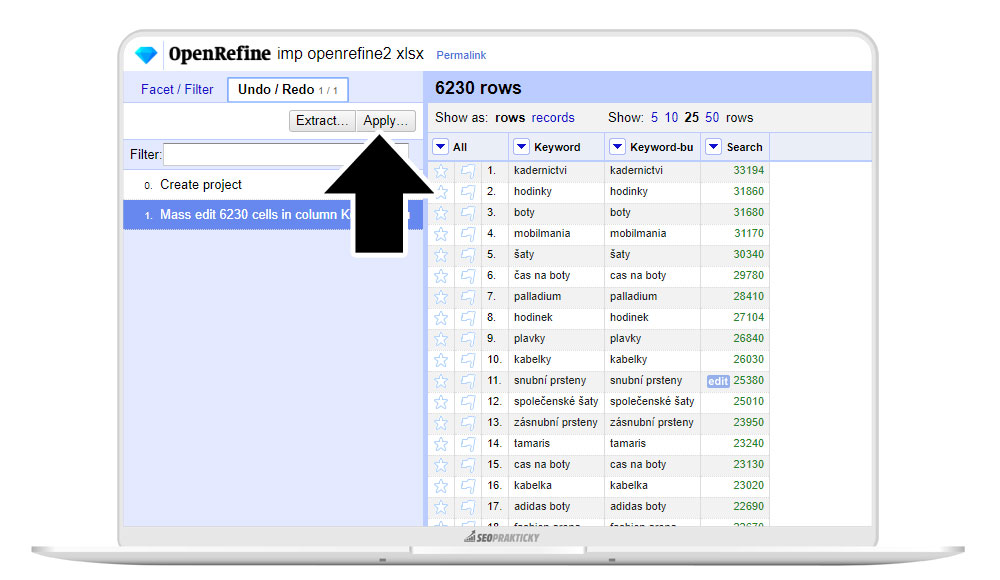
Do funkce Apply vložíme následující kód:
Stáhněte si kód z textového souboru..
[
{
"op": "core/row-reorder",
"description": "Reorder rows",
"mode": "row-based",
"sorting": {
"criteria": [
{
"errorPosition": 1,
"caseSensitive": false,
"valueType": "string",
"column": "
[
{
"op": "core/row-reorder",
"description": "Reorder rows",
"mode": "row-based",
"sorting": {
"criteria": [
{
"errorPosition": 1,
"caseSensitive": false,
"valueType": "string",
"column": "Keyword",
"blankPosition": 2,
"reverse": false
}
]
}
},
{
"op": "core/blank-down",
"description": "Blank down cells in column Keyword",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Keyword"
},
{
"op": "core/multivalued-cell-join",
"description": "Join multi-valued cells in column Keyword-bu",
"columnName": "Keyword-bu",
"keyColumnName": "Keyword",
"separator": "☼"
},
{
"op": "core/multivalued-cell-join",
"description": "Join multi-valued cells in column Search",
"columnName": "Search",
"keyColumnName": "Keyword",
"separator": ", "
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Search using expression value.toString()",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Search",
"expression": "value.toString().replace('.0', '')",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/column-addition",
"description": "Create column Index at index 3 based on column Search using expression jython:array = value\narray = array.split(',')\n\nx = 0\nmax = 0\nindex = 0\n\nwhile x < len(array):\n array[x] = int(array[x])\n if max < array[x]:\n max = array[x]\n index = array.index(max)\n x = x + 1\n\nreturn index",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Index",
"columnInsertIndex": 3,
"baseColumnName": "Search",
"expression": "jython:array = value\narray = array.split(',')\n\nx = 0\nmax = 0\nindex = 0\n\nwhile x < len(array):\n array[x] = int(array[x])\n if max < array[x]:\n max = array[x]\n index = array.index(max)\n x = x + 1\n\nreturn index",
"onError": "set-to-blank"
},
{
"op": "core/column-removal",
"description": "Remove column Keyword",
"columnName": "Keyword"
},
{
"op": "core/column-addition",
"description": "Create column Keyword at index 1 based on column Keyword-bu using expression grel:forEach(value.split('☼'),v,v).get(cells['Index'].value)",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Keyword",
"columnInsertIndex": 1,
"baseColumnName": "Keyword-bu",
"expression": "grel:forEach(value.split('☼'),v,v).get(cells['Index'].value)",
"onError": "set-to-blank"
}
]
Na vaší obrazovce to tedy bude vypadat takto.
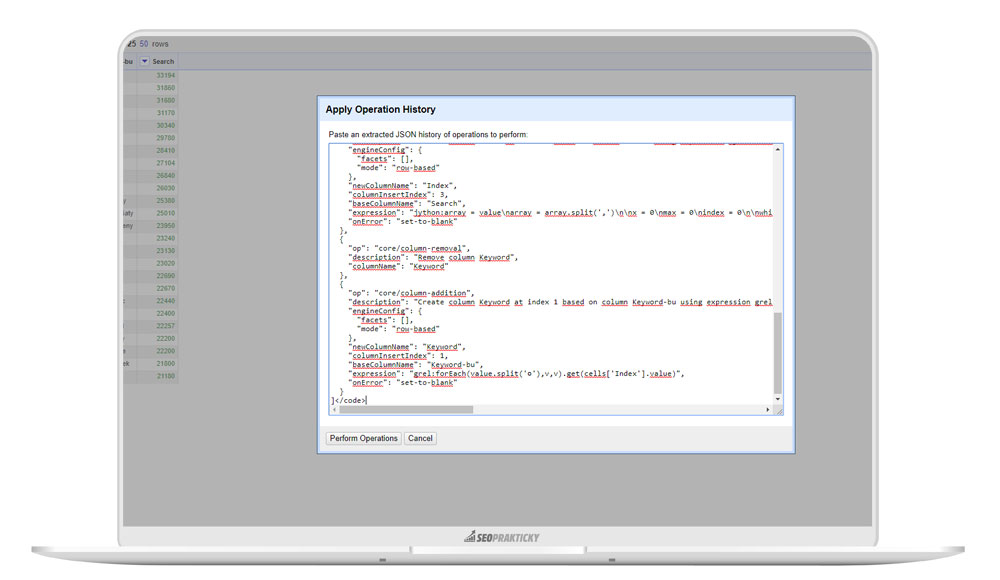
Spusťe skript tlačítkem Perform Operations.
Výsledná tabulka bude vypadat takto.
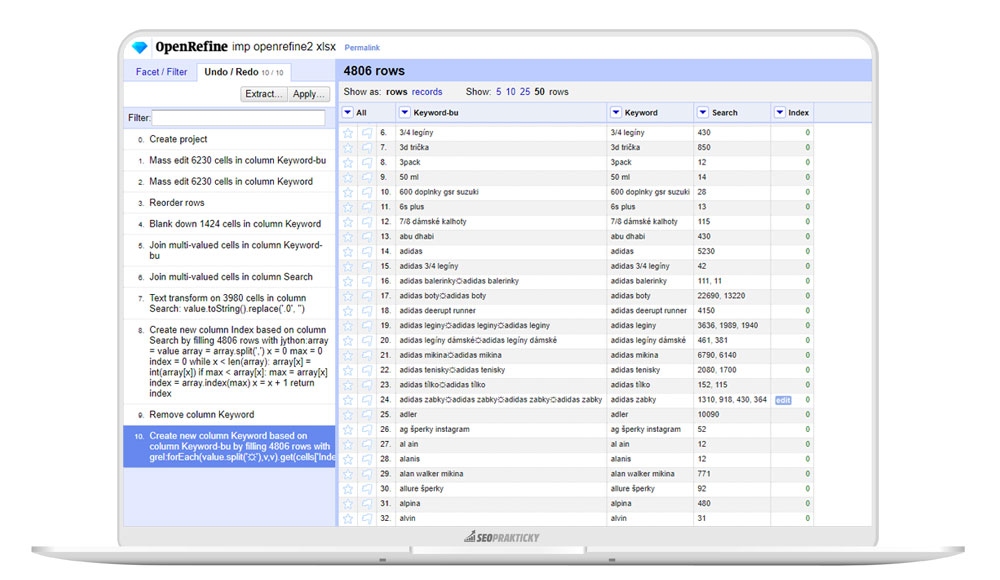
Druhým skriptem práci dokončíme, kdy se nám celá tabulka s daty pročistí.
Stáhněte si kód z textového souboru.
[
{
"op": "core/text-transform",
"description": "Text transform on cells in column Search using expression grel:forEach(value.split(','),v,v.toNumber()).sum()",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Search",
"expression": "grel:forEach(value.split(','),v,v.toNumber()).sum()",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/column-removal",
"description": "Remove column Index",
"columnName": "Index"
},
{
"op": "core/row-removal",
"description": "Remove rows",
"engineConfig": {
"facets": [
{
"type": "list",
"name": "Keyword-bu",
"expression": "isBlank(value).toString()",
"columnName": "Keyword-bu",
"invert": false,
"selection": [
{
"v": {
"v": "true",
"l": "true"
}
}
],
"selectNumber": false,
"selectDateTime": false,
"selectBoolean": false,
"omitBlank": false,
"selectBlank": false,
"omitError": false,
"selectError": false
}
],
"mode": "row-based"
}
},
{
"op": "core/column-reorder",
"description": "Reorder columns",
"columnNames": [
"Keyword",
"Keyword-bu",
"Search"
]
}
]
Takto vypadají výsledná data, která si stačí vyexportovat do excelu a pokračovat v postupu v knize Analýza klíčových slov: Návod krok za krokem na straně 95.